

Bonjour à toutes et tous,
Dans cette newsletter, vous trouverez trois articles concernant :
De Google à xAI comment l’IA recompose le pouvoir mondial
Protéger les contenus de l’appétit des IA
Simuler le réel pour apprendre plus vite
Stéphane
De Google à xAI comment l’IA recompose le pouvoir mondial
Pour écouter cette article avec un podcast réalisé par NotebookLM
En 2025, l’intelligence artificielle n’est ni une hypothèse abstraite ni un gadget spectaculaire. Elle devient une infrastructure de pouvoir. Ce qui se jouait hier dans les labos de recherche et les démonstrations marketing se déplace dans les salles des marchés, les data centers, les régulateurs, les états-majors, … Malheureusement, on continu de parler seulement d’une bataille de modèles alors qu’il s’agit d’une bataille de chaînes complètes, du silicium jusqu’à l’interface, des milliards investis jusqu’à la moindre requête tapée dans un moteur de recherche et au bout de la chaîne de nos cerveaux ! Derrière les noms que tout le monde connaît, Google, Microsoft, OpenAI, Meta, Nvidia, xAI, se dessine une nouvelle cartographie du monde numérique. Une cartographie où la souveraineté ne se mesure plus à la taille du territoire ou au nombre de soldats, mais à la capacité de produire des puces, d’entraîner des modèles géants et de contrôler la distribution de ces modèles dans le quotidien de milliards d’humains. Le futur n’est pas encore écrit. Pourtant il s’ébauche déjà dans quelques fermes de calcul perdue au milieu du désert ou d’une zone industrielle anonyme.
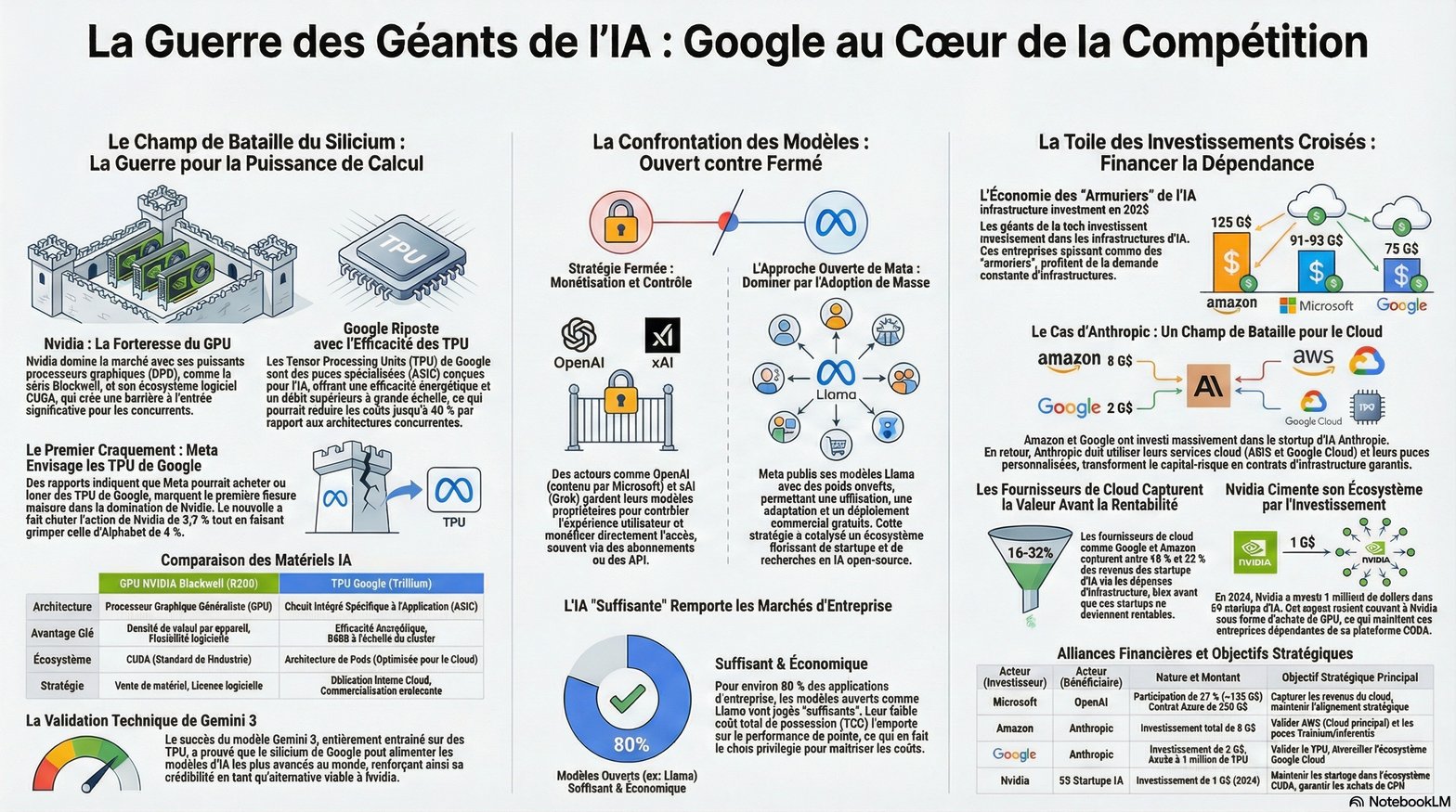
Google d’abord. L’entreprise a décidé de ne plus jouer seulement sur le terrain du logiciel. Elle fabrique ses propres modèles, Gemini 3 et ses déclinaisons, mais aussi ses propres puces, ses propres supercalculateurs, son propre cloud, bref, elle contrôle la totalité de la chaîne et investi sur les prochaines étapes comme l’informatique quantique. Gemini n’est pas un produit isolé, c’est le nouveau moteur de gravité de tout l’écosystème Google. Il se glisse dans la recherche, dans Android, dans Workspace, dans YouTube, sans que l’utilisateur ait besoin de changer d’habitude. En apparence rien ne bouge. En profondeur tout se recompose. Cette intégration totale repose sur une décision stratégique simple, mais redoutable. Google ne veut plus payer la taxe Nvidia. L’entreprise entraîne ses modèles uniquement sur ses TPU (Tensor Processing Unit = unité de traitement de tenseur est un circuit intégré développé par Google pour accélérer les systèmes d'intelligence), déploie ses propres supercalculateurs et commence même à louer cette puissance à des tiers comme Anthropic et peut être Meta demain. Elle devient un fournisseur d’infrastructures pour ses rivaux déclarés. Quand vous consultez un chatbot concurrent, il se peut qu’une partie de sa puissance vienne des puces de Google. Le concurrent devient parfois client avec pour conséquence un rapport de force complexifié.
Face à cette montée en puissance, Nvidia reste pourtant le grand gagnant du moment. Sans elle, la plupart de ces modèles ne fonctionneraient pas. Les GPU Nvidia sont devenus les turbines invisibles de ce début de siècle. Ceux qui n’ont pas les moyens d’inventer leurs propres puces s’alignent sur ce standard de fait. Les labos de recherche, les universités, les startups et une grande partie des géants de la tech dépendent de CUDA (Compute Unified Device Architecture est une technologie propriétaire de GPGPU, c'est-à-dire utilisant un processeur graphique pour exécuter des calculs généraux à la place du processeur central) comme on dépendait autrefois d’un système d’exploitation. Nvidia joue le rôle d’armurier dans une course à l’IA qui ressemble parfois à une ruée vers l’or. Elle vend des pelles, des pelleteuses et les mines entières. Elle investit même directement dans certains prospecteurs, comme xAI ou OpenAI, pour s’assurer qu’ils achèteront bien leurs machines chez elle. Elle finance, elle équipe, elle encaisse. Tant que l’IA repose sur des architectures gourmandes en calcul, tant que chaque progrès se traduit par des millions de GPU supplémentaires, Nvidia reste au cœur du jeu. La question qui reste est de savoir pendant combien de temps.
Sur un autre versant du paysage, OpenAI et Microsoft avancent en duo, presque en symbiose. OpenAI garde l’aura de la startup visionnaire, ChatGPT comme symbole d’une révolution accessible à tous, cette interface qui a mis un visage sur l’IA générative. Mais derrière cette image se cache une dépendance massive aux moyens de Microsoft. Sans Azure, sans les milliards de capital, sans les équipes qui conçoivent des data centers sur mesure, OpenAI ne pourrait ni entraîner ses modèles de frontière ni les proposer à des centaines de millions d’utilisateurs. Microsoft de son côté injecte l’IA dans tout son univers logiciel. Office, Windows, Teams, Azure, chaque brique devient le réceptacle d’un copilote issu des modèles GPT. Cette stratégie transforme une avance technologique en verrouillage économique. L’IA ne se paie pas seulement en abonnements, elle se paie en dépendance durable à une plateforme. Le client qui choisit ce copilote ne choisit pas un modèle en particulier, il choisit un univers complet. Se désengager devient coûteux, techniquement et culturellement. La cage est confortable mais reste une cage.
En face, Meta a pris une décision presque hérétique à l’échelle de ce marché. Publier ses modèles, laisser les poids circuler, encourager la communauté à les adapter, les détourner et les déployer partout. LLaMA devient une sorte de bien commun paradoxal, financé par une entreprise privée, utilisé par des milliers d’équipes indépendantes, parfois par des concurrents directs. Ce choix n’a rien d’altruiste. Plus le monde s’habitue à LLaMA, moins il dépend des API fermées d’OpenAI ou de Google. Plus les développeurs bricolent avec ces modèles ouverts, plus Meta influence les standards de fait de l’écosystème, même quand elle n’encaisse rien directement. Ce pari de l’ouverture a un coût immédiat colossal. Entraîner des modèles massifs, les diffuser, les maintenir, sans facturer chaque requête, pèse forcément sur les comptes. Mais il installe une dynamique différente. Au lieu de concentrer l’innovation dans quelques silos, il encourage une prolifération de dérivés. L’IA cesse d’être un service à la demande en devenant une matière première logicielle que chacun peut façonner. Cela ne garantit pas un monde plus juste ou plus éthique. Cela rend simplement la centralisation plus difficile.
Et puis il y a xAI, l’enfant terrible et non innocent de cette nouvelle géopolitique de l’IA. Elon Musk avance avec sa propre logique, mélange de mégalomanie assumée, d’influence politique et de réel flair stratégique. Grok est présenté comme un assistant insolent, moins filtré, plus réactif, connecté directement au flux de X et, potentiellement, aux capteurs du monde réel de Tesla. En arrière plan, xAI construit un des supercalculateurs les plus ambitieux du moment, installe des turbines au gaz pour l’alimenter, mobilise les chaînes de valeur de Tesla, de SpaceX, de X, et s’adosse à Nvidia pour sécuriser l’accès aux puces. Cette troisième voie se nourrit d’un récit simple. Les autres modèles seraient trop bridés, trop alignés, trop soumis aux sensibilités politiques du moment. xAI promet une IA plus directe, plus crue et trop souvent dangereuse. La liberté d’expression comme argument commercial. La question se déplace de la performance du modèle vers la manière dont nous acceptons de laisser des algorithmes parler à notre place, avec plus ou moins de garde fous. Une IA insolente peut sembler rafraîchissante. Elle peut aussi devenir un accélérateur de chaos comme le montre les différents scandales liés à Grok : propos révisionnistes, relais de théories conspirationnistes, …
On ne peut pas parler de prospective sans glisser Mistral dans le champ. La petite équipe parisienne joue le rôle du caillou coincé dans la chaussure des géants. Mistral aligne des modèles dits en poids ouverts comme Meta, de Mixtral 8x7B hier à la famille Mistral 3 aujourd’hui, avec des variantes Large, Small et même des “Ministral” pensées pour tourner sur une seule carte ou en périphérie du réseau. Leur ambition est limpide. Proposer une intelligence de très bon niveau, multilingue et déjà multimodale, que des banques comme HSBC peuvent auto héberger dans leurs propres data centers pour éviter de confier leurs secrets à un cloud américain tout en gardant la main sur la sécurité. Mistral ne prétend pas battre GPT 5 sur tous les benchmarks. L’entreprise veut plutôt installer l’idée qu’une IA européenne existe, qu’elle peut tourner sur un cluster Nvidia très classique et qu’elle peut s’intégrer dans une PME industrielle allemande, un ministère français ou une startup de santé sans passer par les API des GAFAM. Si ce pari réussit, l’Europe ne gagnera peut être pas la course à la plus grosse usine de puces, mais elle pourra au moins éviter de rester simple consommatrice de cerveaux de silicium fabriqués ailleurs.
De l’autre côté du miroir, les IA chinoises dessinent un troisième bloc qui ne se contente plus d’imiter la Silicon Valley. Baidu pousse la famille ERNIE qui combinent multimodal et raisonnement approfondi, proposées gratuitement au grand public local et via une plateforme Qianfan pour les entreprises. Alibaba fait grandir Qwen, Tencent déroule Hunyuan, Huawei avance ses Pangu sur ses propres puces Ascend, tandis que des acteurs plus récents comme DeepSeek publient des modèles ouverts très agressifs en prix qui bousculent tout le marché domestique. Le tout se développe sous contrôle politique serré, puisque chaque modèle grand public doit obtenir une autorisation et intégrer des garde fous alignés sur les priorités du Parti. Officiellement ces systèmes visent surtout le marché intérieur avec une priorité donnée au chinois et aux usages locaux. En pratique ils deviennent aussi un laboratoire géant pour des architectures plus sobres et des stratégies de contournement des sanctions américaines sur les GPU, grâce à des grappes de puces domestiques comme Kunlun ou Ascend. Vu d’Europe, ces modèles restent encore un bruit de fond lointain, en grande partie pour des raisons de langue et de régulation. Pourtant ils pèsent déjà sur les prix, sur l’accès au calcul et sur la manière dont la planète définira demain ce qu’une IA a le droit de dire ou de taire.
Si l’on prend un pas de recul, plusieurs lignes de fracture traversent ce paysage. L’ouverture contre la fermeture. Certains acteurs misent sur le secret, la rareté, l’accès contrôlé par API. D’autres publient leurs modèles, leurs architectures, parfois même leurs jeux de données. Cette opposition structure au delà de la technique la manière dont la valeur circulera demain. Un monde dominé par des modèles fermés concentre pouvoir et profits dans quelques mains. Un monde où l’open source progresse ne garantit pas l’égalité, mais il réduit au moins la possibilité d’une digitalocratie totale.
Autre fracture, la verticalisation contre l’alliance. Google choisit de tout intégrer en interne. Microsoft préfère tisser des partenariats, avec OpenAI, avec Meta, avec d’autres. Nvidia vend à tous, quitte à financer ceux qui menacent ses plus gros clients. Les nuages se chevauchent, les participations croisées brouillent la frontière entre alliés et concurrents. Celui qui utilise Gemini pour un projet peut très bien vendre par ailleurs un service fondé sur LLaMA ou GPT. La carte des alliances ressemble à un échiquier où chaque camp joue sur plusieurs plateaux en même temps.
Pendant ce temps, le débat public se focalise souvent sur les agents conversationnels, leurs dérapages ou encore leurs prouesses. Nous discutons de style de réponse alors que le véritable enjeu se situe ailleurs. Il se situe dans la concentration de la puissance de calcul, dans le contrôle des puces, dans les contrats d’exclusivité entre fournisseurs de cloud et laboratoires d’IA, dans la capacité des grands acteurs à financer à la fois les modèles et les infrastructures qui les rendent possibles. Le citoyen voit des robots qui parlent. Le pouvoir se joue dans des salles de conseil où l’on signe des accords à plusieurs milliards. Cette concentration ne reste pas sans conséquence. Elle redessine notre rapport à la vérité, à la connaissance, à la décision et impacte durablement notre libre-arbitre. Quand quelques acteurs contrôlent les moteurs d’indexation, les modèles de langage et l’infrastructure de calcul, ils deviennent de facto les grands éditeurs du réel. Ils choisissent ce que les modèles voient, ce qu’ils mémorisent ou encore ce qu’ils oublient. Ils déterminent la frontière entre l’erreur acceptable et le discours inacceptable. Dans un monde saturé de contenus synthétiques, cette capacité de filtrage se transforme en pouvoir politique. Silencieux. Persistant. Profond.
Il faut ajouter un autre coût, beaucoup plus concret cette fois. Le coût énergétique et matériel. Derrière chaque démonstration brillante d’un modèle qui code, dessine ou argumente, il y a des milliers de puces qui chauffent, des centrales électriques qui tournent, des minerais extraits, des terres rares, de l’eau utilisée pour le refroidissement, ... L’IA se présente comme une intelligence immatérielle. Elle repose en réalité sur une intensification très matérielle de notre pression sur le vivant. Plus nous alimentons cette course à la taille des modèles, plus nous creusons la dette écologique qui l’accompagne.
Nous arrivons alors à une tension centrale. D’un côté, l’IA promet une expansion de nos capacités, un gain de productivité, un soutien précieux pour la recherche, la santé, l’éducation et la création. De l’autre, elle menace d’accélérer l’érosion de notre attention, de notre esprit critique et de notre autonomie. À force de déléguer les diagnostics, les synthèses, les choix, nous risquons une forme de dette cognitive. Le cerveau humain se désinvestit de ce qu’il sait pouvoir externaliser. L’outil devient béquille. Puis prothèse. Puis substitut.
L’état des lieux en 2025 ressemble donc à un carrefour. Nous disposons déjà de tout ce qu’il faut pour basculer vers une concentration extrême du pouvoir numérique. Quelques entreprises capables de maîtriser toute la chaîne de valeur, des états souvent en retard avec en prime des citoyens fascinés mais peu armés. Nous disposons aussi de tout ce qu’il faut pour choisir une autre trajectoire. Des modèles ouverts qui progressent vite, des initiatives de régulation qui tentent d’anticiper, des communautés techniques qui refusent l’opacité totale et des voix qui réclament des communs numériques. La question décisive ne sera pas de savoir qui possédera le modèle le plus intelligent. Elle sera de savoir qui décidera des règles du jeu, des garde fous, des standards d’accès, des droits d’usage, ... Tant que ces choix restent confinés aux conseils d’administration et aux accords bilatéraux, nous risquons de découvrir l’avenir de l’IA comme on découvre une facture. Trop tard, trop cher et surtout trop engagé pour faire machine arrière.
Nous avons laissé quelques acteurs construire les moteurs de notre futur cognitif. Nous n’avons pas encore décidé ensemble ce que nous voulons en faire. Il est urgent de reprendre la main avant que le futur ne se charge de nous rappeler que l’intelligence, artificielle ou non, n’est jamais neutre.
On a posé le décor de 2025. Maintenant il faut accepter une chose simple même si elle agace les esprits rationnels. L’avenir de l’IA ne suivra pas un scénario propre et unique. Il suivra une trajectoire bancale avec des bifurcations, des coups de force, des découvertes imprévues et des décisions politiques prises à trois heures du matin sous pression médiatique.
Passons maintenant à un exercice de prospective avec cinq futurs possibles se dessinent déjà tout en sachant qu’aucun ne se réalisera exactement tel quel mais tous pèsent sur les choix des acteurs actuels, parfois sans qu’ils l’avouent.
Scénario 1. Le duopole poli Google contre Microsoft OpenAI
Dans ce futur, la décennie se termine avec deux blocs bien installés. D’un côté Google pose Gemini comme couche de base de tout son univers. L’assistant s’insère partout. Sur Android on parle à Gemini pour organiser son agenda, négocier ses factures, préparer son voyage, … Dans Gmail les réponses suggérées ne sont plus trois lignes au style neutre, mais des propositions quasi prêtes à signer. Sur YouTube un bouton résume, traduit, chapitre et analyse. La frontière entre moteur de recherche et agent personnel disparaît.
De l’autre côté Microsoft et OpenAI déroulent leur stratégie patiente. Le nom ChatGPT reste dans le langage courant, mais sous le capot les modèles se succèdent. GPT 5 puis 6 se branchent toujours plus profondément sur Windows, sur Office, sur Teams. Dans beaucoup d’organisations on ne “utilise pas de l’IA”. On “demande au copilote”. L’outil devient un réflexe comme la touche copier coller à l’époque.
Dans ce scénario la force économique finit par l’emporter sur les rêves d’écosystèmes ouverts. Les directions informatiques préfèrent des solutions clef en main, contractuelles, assurables et confortables. Pour un hôpital, une banque, une administration, la promesse “Google ou Microsoft assumeront en cas de problème” compte davantage qu’un discours sur les communs numériques. Les projets basés sur des modèles ouverts restent florissants mais rarement au cœur des systèmes critiques.
Nvidia dans cette histoire continue de vendre des montagnes de GPU aux deux camps. Les sociétés qui avaient tenté la voie des puces maison arrivent à quelque chose d’honorable sans pour autant renverser la table. Le rapport de force se stabilise. On s’habitue à vivre dans un monde où deux grands ensembles technologiques produisent la quasi totalité des assistants avec lesquels on interagit chaque jour en Europe, aux USA et chez leurs alliés.
Le risque évident saute aux yeux. La diversité réelle des points de vue se réduit, même si l’illusion de choix demeure. On change d’interface, pas de matrice. Deux conseils d’administration, quelques gouvernements et un petit cercle d’ingénieurs décident de ce que “sait” l’IA grand public. Tout le reste se cale sur cette normalisation douce. Evidemment le pendant existe avec les IA chinoises.
Scénario 2. Le grand foisonnement open source
Ici Meta ne lâche pas l’affaire. LLaMA 4 puis 5 montent en qualité, jusqu’à rejoindre puis dépasser certains modèles fermés sur des usages ciblés. Surtout, des centaines d’équipes s’en emparent. Une collectivité territoriale en Europe utilise une variante entraînée sur son droit local pour automatiser une partie de ses procédures. Une association de médecins africains publie un dérivé spécialisé dans les pathologies tropicales nourri de données qui n’intéressaient personne dans les pays du Nord. Un éditeur scolaire développe un tuteur pédagogique capable d’expliquer les maths avec l’accent et les références culturelles des élèves. Peu à peu une évidence s’installe : les modèles fermés gardent une petite avance brute mais l’écosystème ouvert gagne sur l’adaptation. Là où OpenAI et Google doivent arbitrer entre des millions de demandes, une communauté locale peut adapter son modèle à un secteur avec une finesse que les géants ne chercheront jamais.
Les états, eux, commencent à comprendre que leur souveraineté ne peut reposer uniquement sur des licences commerciales. Certains pays financent directement des modèles ouverts auditables avec un cahier des charges clair sur la traçabilité des données. L’équivalent des grandes bibliothèques nationales se reconstitue mais sous forme de poids de réseaux de neurones et de jeux de données publics.
Nvidia conserve un rôle central, mais voit apparaître des concurrents plus crédibles. Un acteur asiatique parvient à sortir un accélérateur IA suffisamment bon à un coût inférieur. Des consortia publics privés déploient des centres de calcul régionaux où tournent des modèles ouverts à disposition de la recherche, des PME et des médias, sans passer par les grands clouds américains.
Dans ce film là, la carte du pouvoir devient plus brouillée. Il existe toujours des géants, mais aucune entreprise ne tient seule la clé du futur cognitif. Évidemment tout n’est pas rose. Les modèles ouverts alimentent aussi de nouvelles formes de fraude, de propagande ou encore de manipulation. Les régulateurs courent derrière. Mais au moins la discussion ne se résume pas à “faut il faire confiance à X ou Y”. Elle porte sur l’architecture générale de notre espace numérique.
Scénario 3. L’empire des infrastructures
On arrête de regarder les modèles et on suit l’électricité. Dans cette version du monde, l’IA devient d’abord une affaire de câbles, de centrales, de fonderies, de silicium et de terres rares. Les pénuries de puces, les tensions géopolitiques et le coût énergétique de l’entraînement finissent par imposer un constat brutal. Le goulot d’étranglement est lié à la capacité à faire sortir de terre des usines de fabrication de semi conducteurs et des data centers reliés à des sources d’énergie stables. Nvidia, TSMC, quelques producteurs de mémoire et d’interconnexions ultra rapides pèsent davantage que les logos visibles du grand public. Les arbitrages climatiques deviennent inévitables. Un pays choisit de limiter le nombre de grands modèles entraînés sur son sol pour tenir ses engagements de réduction d’émissions. Un autre, au contraire, sacrifie une partie de ses objectifs environnementaux pour attirer les “fab” et les fermes de calcul sur son territoire et un autre ne se pose aucune question du fait de sa négation du réchauffement climatique lié à l’activité humaine. La carte de l’IA commence à ressembler à celle du pétrole à une autre époque. Quelques zones concentrent la puissance alors que les autres négocient des accords d’accès.
Dans cette histoire, Google et Microsoft ne disparaissent pas. Ils deviennent clients stratégiques de ces infrastructures ou les intègrent verticalement lorsque leur trésorerie le permet. Mais le centre de gravité se déplace. De la même manière que certains états n’ont jamais vraiment maîtrisé leurs systèmes d’armes parce qu’ils dépendaient d’un fournisseur étranger, certains pays prennent conscience que leur souveraineté numérique repose sur des contrats industriels dont ils ne contrôlent pas les clauses techniques.
Pour les citoyens, ce scénario se voit peu à court terme. Les assistants fonctionnent, les interfaces s’améliorent et les applications se multiplient. La vraie facture se manifeste ailleurs. Des arbitrages budgétaires défavorables à d’autres infrastructures, des tensions sur le réseau électrique, des décisions discrètes sur l’emplacement de nouvelles usines et sur la main d’œuvre nécessaire. L’IA apparaît alors moins comme une “intelligence” et davantage comme une nouvelle forme de grande industrie lourde. Très sophistiquée en surface et très classique en profondeur.
Scénario 4. Le coup de frein politique
Une série d’incidents change la donne. Un scandale majeur de désinformation orchestrée avec des modèles avancés. Une faillite industrielle liée à une décision prise sur la base d’un système automatique mal calibré. Un procès retentissant où les victimes obtiennent gain de cause face à une entreprise qui s’abritait derrière son “algorithme propriétaire”. Les régulateurs, souvent en retard, réagissent cette fois avec vigueur. L’Europe applique un AI Act plus strict que prévu. Les États Unis, sous la pression de l’opinion, créent après la prochaine élection présidentielle une autorité de régulation fédérale dédiée à l’IA avec des pouvoirs d’enquête étendus. D’autres régions suivent des voies similaires. L’entraînement de modèles au delà d’une certaine taille nécessite une licence et une documentation détaillée sur les données utilisées et les mécanismes de sécurité. Dans ce cadre, les petits acteurs peinent à suivre la cadence administrative. Les très grands, eux, encaissent du fait de l’existence en interne d’équipes juridiques et de conformité. Paradoxalement, une régulation née d’une inquiétude légitime peut renforcer les positions dominantes.
Cependant la pression citoyenne ne disparaît pas. Des ONG, des syndicats et des collectifs professionnels réussissent à imposer des contre pouvoirs. Des “comités d’algorithmes” naissent dans les grandes villes pour examiner les systèmes utilisés par les services publics. Des clauses de transparence s’invitent dans les conventions collectives. On voit apparaître des chartes de “non délégation totale”, par exemple dans le journalisme ou la médecine, qui garantissent une part minimale de décision humaine non automatisable. Les scénarios open source se trouvent pris en étau. D’un côté certains régulateurs les regardent avec méfiance, de peur de modèles incontrôlables et de l’autre, ils représentent parfois la seule manière crédible de satisfaire des obligations de transparence sur les données et les architectures. Le compromis passe par des labels, des certifications ainsi que des mécaniques de responsabilité partagée.
Ce futur là ne ressemble pas à une dystopie technophobe. L’IA reste omniprésente. Simplement son déploiement se heurte à des contre-pouvoirs structurés. Pour signer un contrat avec un fournisseur d’IA, on passe par des débats publics, des évaluations d’impact et des négociations sur la gouvernance. C’est certes plus lent et moins “fluide” mais c’est aussi plus adulte.
Scénario 5. La rupture imprévue
Deux variantes opposées coexistent.
Dans la première, une vraie rupture technologique survient : une nouvelle manière de faire de l’IA, avec beaucoup moins de paramètres, de données et de calcul. Une architecture plus proche de la cognition humaine ou quelque chose venue des neurosciences ou encore un mélange IA classique plus symbolique remis au goût du jour. La barrière à l’entrée chute. Des équipes jusqu’ici périphériques se retrouvent soudain devant. Une université sort un prototype qui met en défaut les modèles géants sur certaines tâches cognitives complexes. Une PME reprend cette approche et la transforme en produit. Un mouvement de rattrapage se met en place. Les investissements colossaux réalisés dans des fermes de GPU se déprécient plus vite que prévu. Le pouvoir se déplace de ceux qui possèdent les machines vers ceux qui comprennent la nouvelle architecture.
Dans la seconde variante, ce n’est pas une percée qui fait bouger les lignes mais un choc négatif. Crise énergétique sévère, conflit armé affectant la production de semi conducteurs ou encore une catastrophe climatique forçant des rationnements d’électricité. L’IA n’est alors plus la priorité. Des gouvernements décident de réserver les capacités de calcul à des usages jugés vitaux comme la recherche médicale ou la gestion des réseaux au détriment des assistants conversationnels grand public. Les modèles existants continuent de tourner, mais l’ère du “toujours plus gros” s’interrompt brutalement. Pour les entreprises qui avaient tout misé sur des modèles géants cette rupture fait l’effet d’un mur. Les stratégies centrées sur des modèles plus petits, frugaux, embarqués, se retrouvent soudain adaptées au nouveau contexte. Là où les géants avaient une longueur d’avance purement quantitative, ils doivent réapprendre l’art de faire mieux avec moins.
Dans ces deux variantes, une constante revient. L’illusion de la linéarité disparaît. On découvre que l’IA n’est pas un fleuve tranquille qui s’écoule vers une AGI forcément plus puissante et plus chère. C’est un champ de forces, traversé par des contraintes physiques, sociales et politiques. Les leaders d’hier peuvent se retrouver à défendre leurs positions avec les mêmes réflexes que les anciens empires industriels en fin de cycle.
Ces cinq scénarios ne sont pas exclusifs. Certains s’imbriqueront. On peut très bien imaginer un duopole relatif sur les usages grand public, un foisonnement open source dans les niches professionnelles, une régulation plus serrée sur certains domaines sensibles et une tension croissante sur les infrastructures énergétiques. Le réel se chargera de mélanger ces lignes. Ce qui importe, pour nous qui regardons tout cela en 2025, consiste moins à miser sur le “bon” scénario qu’à se poser les questions suivantes : dans lequel de ces futurs avons nous envie de vivre ? Dans lequel acceptons nous que nos enfants grandissent, apprennent, travaillent et se trompent ?
Les choix des géants de l’IA se jouent maintenant, à coups de milliards et de partenariats stratégiques. Les nôtres aussi. Ils se joueront dans les lois que nous laisserons passer ou non, dans les outils que nous choisirons au quotidien, dans la façon dont nous exigerons ou pas un droit de regard sur ces systèmes qui s’invitent déjà dans nos décisions.
Protéger les contenus de l’appétit des IA
Cloudflare, décrété justicier du Web, a déclaré que depuis le 1ᵉʳ juillet 2025, l’entreprise a bloqué 416 milliards de requêtes de bots IA tentant de piller du contenu en ligne. Ce chiffre vertigineux révèle l’ampleur de la ruée vers les données que connaît l’ère de l’IA. Pour des créateurs de contenu (médias, blogueurs et artisans du Net), c’est une bouffée d’air : fini le pillage gratuit, place à l’autorisation, voire à la rémunération. Cloudflare propose désormais un modèle « pay-per-crawl » : si un bot IA veut ingurgiter un site, il doit payer.
Mais derrière cette protection, se cache une bifurcation profonde de l’écosystème numérique. L’équilibre se déplace : du trafic web qui est le fondement historique de la monétisation vers des accords explicites entre créateurs et IA. Certains diront que c’est un renforcement de la souveraineté intellectuelle. D’autres, qu’on érige des péages à l’accès, fragmentant un Internet jusque-là global au détriment de l’ouverture, de la diversité, de la libre circulation des idées.
Au passage, selon Cloudflare, Google voit 3,2 fois plus de pages qu’OpenAI, 4,6 fois plus que Microsoft, et près de 5 fois plus qu’Anthropic ou Meta.
Pour moi, c’est un signal clair : l’ère de l’IA impose que l’humain reprenne la main pour protéger ce qui fait sens (la créativité, la pensée ou encore la singularité). Adopter une vision tournée vers l’avenir, c’est accepter que chaque page, chaque œuvre, chaque idée mérite respect et peut-être, au passage, retrouver cette humanité multiple, riche… dans un monde où l’IA peut tout copier, sauf ce qui la rend inutile à savoir la différence.
Simuler le réel pour apprendre plus vite
Des copies quasi parfaites des sites internet d’Amazon, d’Airbnb, de Gmail, de United Airlines, …construites en douce par des startups pour entraîner des agents d’IA à cliquer, acheter, réserver et négocier, comme un humain idéalement docile. Ces clones servent de terrains d’exercice où les machines répètent des milliers voir des millions de fois les mêmes gestes, loin des pare feux des vrais sites et des limites imposées aux robots.
La promesse peut sembler séduisante. Le rêve de tout cadre noyé sous les tâches numériques : une IA capable d’organiser un voyage complet, de gérer une boîte mail saturée et de remplir des formulaires administratifs à notre place. Mais derrière ces copies se cache une copie simpliste du monde. Une économie où l’on automatise des métiers entiers avec à la clé des gains de productivité pour quelques-uns et une nouvelle vague de déclassement pour d’autres. Surtout, ces Shadow Sites poussent encore un peu plus loin la fuite en avant actuelle. Après avoir aspiré nos textes, nos images et nos voix, l’industrie bâtit désormais un internet fantôme où les machines s’entraînent entre elles à partir de simulacres de nos services quotidiens. Nous avançons vers une digitalocratie silencieuse où le pouvoir réside dans des environnements opaques qui reproduisent la réalité sans jamais lui rendre de comptes.
Il est temps de rappeler une évidence. On ne joue pas impunément avec des copies du réel. Un jour ou l’autre, c’est le réel qui encaisse.
Bonnes métamorphoses et à la semaine prochaine.
Stéphane










